




如今,每個人都在宣稱自己正在學習AI。然而,現實情況是絕大多數人只是在努力成為一名更高級的“Googler”。
如果你的AI教育僅限於背誦提示詞(prompt)範本,或者研究如何用特定的語氣讓Claude寫出更好的代碼,那你並不是在學習AI。你只是在學習如何使用一個UI(user interface,使用者介面),就像學習如何操作一台自動售貨機,你學會了投幣和按鍵,卻對機器內部如何處理支付、如何調度貨物的物理邏輯一無所知。
AI模型並不知道事實
目前的行業正被一群掌握了介面而非智慧的AI專家所淹沒,他們隨處可見,如開辦打着「8小時精通ChatGPT」旗號的課程;在不看原始程式碼的情況下,機械地複製LangChain的樣板代碼;調用一個API介面,拿到結果就直接推向生產環境,連最基本的評估集(eval suite)都沒有。
這些都是表層技能,極其脆弱。當模型架構發生演變,或者抽象層發生位移時,這些所謂的提示詞工程師擁有的只是一腦子過時的知識。將工具使用者與真正的AI工程師區分開來的只有一個真相:AI模型並不知道事實,它們只是在高維表徵空間(high-dimensional representation space)中導航概率。
當你問大型語言模型(LLM):蘋果公司的CEO是誰時,它並沒有去查資料庫,也沒有檢索知識圖譜,它沒有人類意義上的記憶。
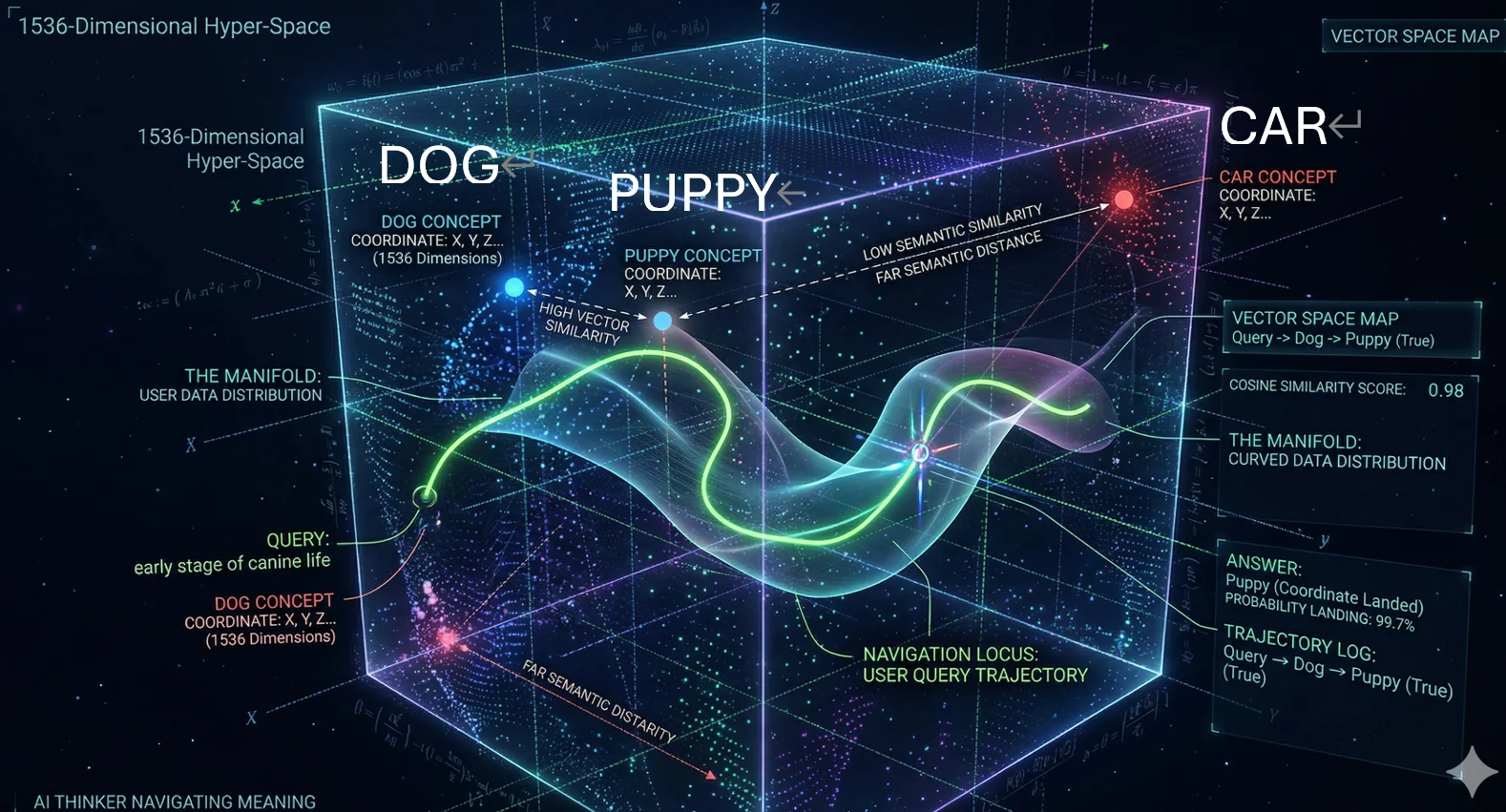
尋找答案是一條軌跡
在傳統軟體中,資料是離散的。一個字串就是一串字元,如“A==A”。但在AI的世界裏,資料是連續的,文字、圖像、概念,一切都被轉化為一串被稱為「向量」(vector)或「嵌入」(embedding)的數字清單。
筆者用AI製作了一張概念圖,但這張圖不是只有經緯度,而是擁有1536個維度(只是舉例,可達更高維度)。在這個極其複雜的超空間裏,意義是由位置定義的,例如“Dog”的概念位於特定的座標,“Puppy”離「狗」非常近,“Car”離它們非常遠。當模型給你一個正確答案時,它並不是記住了答案,而是成功地導航到了流形(Manifold,一種彎曲或複雜的數學空間,用作儲存資料),最終降落在答案概率上所屬的座標點。
這就解釋了為什麼有AI幻覺(AI hallucination)。模型沒有撒謊,也沒有困惑,它只是根據你提示詞的軌跡,行駛到了一個在數學上感覺正確的座標,在現實世界中卻是「事實真空」,它只是降落在了「真理中心」附近的「郊區」。例如,一個法律摘要程式會將「被告」替換為「原告」,因為這兩個字的向量空間非常接近。又例如,一個醫療機器人會建議一種統計上可能有效、但生物學上致命的劑量。
餵更多資料也能失效
一旦你理解到AI是一個在幾何空間運行法則,許多典型的失敗案例就有了合理的解釋:為什麼餵更多資料會失效?你不能僅僅透過往上下文視窗,塞更多文字來修復邏輯推理。如果模型的內部地圖(預訓練權重)認定A靠近B,推理時的上下文,很難從根本上重塑這種幾何引力。
為什麼模型表現得自信、但答案錯誤?其自信僅僅是概率曲線的陡峭程度。模型可以對一條完全錯誤的路徑擁有99.9%的數學確定性。這就像因為GPS訊號漂移,你正以高速跑向錯誤的方向。
2026年 如何學好怎樣用AI?
工具使用者透過閱讀來判斷AI的答案是否正確;而AI思考者則測量語義距離。大多數人落後並非因為起步晚,而是因為他們學習的概念錯了。AI素養並非知道該在框框裏輸入什麼,而是確切地知道為什麼你不應該相信輸出的結果。
如果你想在2026年的AI浪潮中生存,請開始做這三件事:研究失敗模式,不要只看模型做對了什麼,嘗試去找到它能犯錯的邊界;精通評估(evals):系統地測試、衡量和改進大型語言模型和AI代理的輸出品質的框架和流程;強化系統化思考,要知道模型只是一個元件,真正的魔力在於路由、存儲層和驗證器。


















































